
El Hadoop Distributed File System (HDFS) es uno de los componentes fundamentales del ecosistema Apache Hadoop, una plataforma diseñada para el almacenamiento y procesamiento de grandes volúmenes de datos distribuidos. HDFS permite almacenar datos de manera distribuida en múltiples nodos, brindando alta disponibilidad, escalabilidad y resistencia frente a fallos, aspectos esenciales en entornos de big data.
¿Cómo funciona?
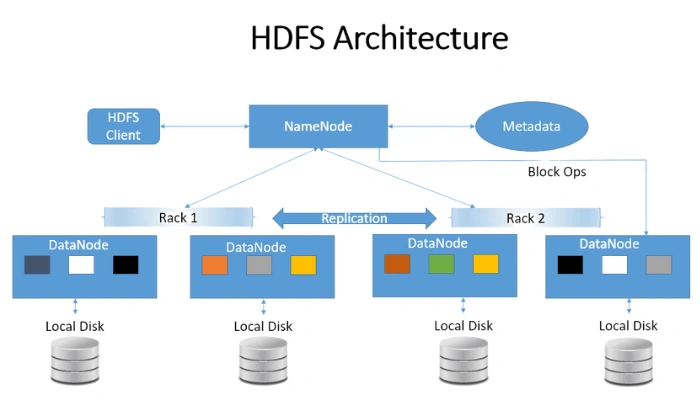
HDFS se basa en una arquitectura maestro-esclavo, donde el NameNode actúa como el nodo principal y controla la distribución de los archivos en diferentes nodos esclavos, llamados DataNodes. Los archivos se dividen en bloques de datos y se almacenan en diferentes nodos dentro del clúster, con la posibilidad de replicar los bloques para asegurar su disponibilidad en caso de fallos en alguno de los nodos. Esta replicación también permite que el sistema mantenga el rendimiento incluso cuando alguno de los DataNodes está inactivo o presenta fallas.
Principales características de HDFS
- Almacenamiento distribuido: HDFS divide y distribuye los datos en bloques almacenados en diferentes nodos, lo que facilita el manejo de grandes volúmenes de datos.
- Tolerancia a fallos: La replicación de los bloques en diferentes nodos garantiza la recuperación de datos ante fallos o interrupciones en el sistema.
- Alta escalabilidad: HDFS permite añadir nuevos nodos al clúster sin afectar el rendimiento, siendo ideal para entornos de big data que requieren escalabilidad.
- Acceso a datos en paralelo: El acceso distribuido permite realizar operaciones en paralelo, optimizando el tiempo de procesamiento de datos.
Componentes clave de HDFS
- NameNode: Es el nodo maestro que gestiona la ubicación de los archivos y metadatos en el sistema. Coordina las solicitudes de los clientes y mantiene el registro de qué bloques de datos están en cada DataNode.
- DataNodes: Son los nodos donde realmente se almacenan los bloques de datos. Cada DataNode informa al NameNode sobre el estado de sus bloques para asegurar la disponibilidad y la integridad de los datos.
- Secondary NameNode: Actúa como respaldo del NameNode y realiza copias periódicas de los metadatos. No sustituye al NameNode en tiempo real, pero ayuda a reducir la carga y a prevenir la pérdida de metadatos.
Beneficios de HDFS
- Optimización del costo de almacenamiento: Al utilizar hardware común y accesible, HDFS permite almacenar grandes cantidades de datos sin los altos costos asociados a los sistemas de almacenamiento tradicionales.
- Soporte para grandes archivos: Diseñado para almacenar archivos de gran tamaño, HDFS es ideal para aplicaciones de big data que manejan petabytes de información.
- Integración con el ecosistema Hadoop: HDFS es totalmente compatible con otras herramientas de Hadoop, como MapReduce, lo que facilita el procesamiento y análisis de datos masivos.
Limitaciones de HDFS
Si bien HDFS ofrece grandes ventajas, también tiene limitaciones:
- No es adecuado para datos en tiempo real: Debido a que fue diseñado para procesos batch, HDFS no es ideal para la gestión de datos en tiempo real o de baja latencia.
- Límite de pequeños archivos: HDFS no maneja de manera eficiente una gran cantidad de archivos pequeños, ya que el NameNode almacena metadatos de cada archivo, lo que puede llevar a problemas de rendimiento.
Aplicaciones y casos de uso de HDFS
HDFS se utiliza ampliamente en sectores que necesitan almacenar y procesar grandes volúmenes de datos, como el comercio electrónico, las redes sociales, y los servicios financieros. Las aplicaciones incluyen:
- Análisis de Logs: Procesamiento de grandes volúmenes de logs para obtener insights de uso y rendimiento.
- Análisis de sentimientos en redes sociales: Recopilación y análisis de grandes volúmenes de datos de redes sociales para entender la percepción del público.
- Análisis de fraude en finanzas: Almacenar y analizar datos históricos para detectar patrones de fraude.
Conclusión
HDFS es una solución fundamental para el almacenamiento de datos distribuidos en entornos de big data. Su capacidad para gestionar grandes volúmenes de información de manera escalable y su integración con el ecosistema de herramientas de Hadoop lo convierten en una herramienta esencial para las empresas que buscan aprovechar el potencial de sus datos.

